
Machine Learning
Master’s Thesis
The focus on categorizing newspaper articles on the basis of gender, traditional machine learning techniques for classifying the text having been applied. Male and female writing styles were been identified.The New York Times Annotated Corpus licensed by Linguistic Data Consortium, containing approximately 1.8 million articles has been used.
The article text is sorted, —articles containing definite male female author bylines and labels have been considered for classification and prediction initially, The text contains name of the author which has been matched against a male female labelled list to determine the gender of the author name.
We try to predict the author of the authorless articles (containing articles written by collective boards such as editorials) on the basis of the model we built. We also conduct a comparative study of different machine learning techniques like logistic Regression, Decision Tree Classifier, Support Vector machines and a few more to determine which learning method performs the best with the corpus.
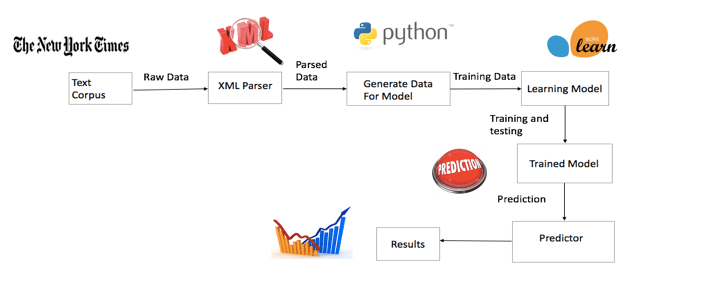
The model parsed approximately 1.8 million documents. Approximately 500,000 documents, article consisted of solo male and solo females, The Logistic Regression when used to classify the dataset, gives us accuracy of 85.1 per cent. The precision, recall and f1 scores for the male and the female labels for a sample of dataset are given below in the table:

I built a model for gender prediction, by using the New York Times Annotated Corpus, assigning Male and Female labels to the articles. The corpus is split into 90 percent training and 10 percent testing. We perform 10 way cross validation-on a sample of the dataset to select the model which best fits this corpus.
Logistic Regression seems to performing the best for this specific corpus. We get accuracy of 85.81 percent on a sample of dataset and low recall scores. Accuracy score of 82.78 percent is obtained for both male and female labels on testing the model on the whole dataset the performance improves as we increase the threshold.
The threshold is set to 65 percent to balance the recall and thereby increasing the performance of the learning model. The model predicts 79.61 percent articles to be authored by male and 20.27 percent documents to be authored by female.
Working with Data Scientists
As a Full Stack Developer, I worked extensively with data scientists to integrate machine learning codes developed and hosted in python servers. Created extensive analytics and created several API’s to fetch the data from the python servers and visualize and display it in comphrensive dashboard to create a unique experience for ML application consumers.
Get In Touch
- devisha1@umbc.edu
- (240) 364 4641
